by Vas Mylko
The Question
I’m a New Yorker, I want to do a road trip from Los Angeles to Salt Lake City, I want to visit Hoover Dam and Sundance Resort, I’m curious to visit more cool points but I don’t know about them, I want See & Do at each point, the whole journey must be 7 days and $2,000 for 2 travelers by 1 car, I want a great journey, what is the best trip plan in my conditions?
The Answer
Navigate to https://curiosio.com and enter what you know and what you want, and get the answer — most interesting trip plan in your context.

A unique solution is found for a unique question. The answering engine makes the unique answer by running computation. The computation progress is visualized with the crawling red progress bar. We do our best to return results in 10s for the math problem that doesn’t guarantee the results in any predictable time. There is The Math section with details below.
Curiosio is a technology for a new era of independent travel. It will start in post-COVID new world. The old 20-year era was ending anyway. Ridiculous 10 years of overtourism have ended when the world abruptly shut down. Future independent travel will be smarter, healthier, and better for the planet and for the people.
The Phenomenon
By building Curiosio as search/answering engine we experienced the phenomenon of computational irreducibility. It is impossible to shortcut the program to get the good solution — trip plan that you like, that is good when you do due diligence and verify it down to details. It is impossible to predict what the trip plan will look like without running the amount of computing that cannot be reduced. Computational Irreducibility was proposed by Stephen Wolfram in his book A New Kind of Science.
Some computations cannot be sped up. The principle of computational irreducibility says that the only way to determine the answer to a computationally irreducible question is to perform, or simulate, the computation.
— Stephen Wolfram
The Math
For the curious geeks, here is a simplified mathematical model of the optimization problem. To be in sync with the question on top of this post — s is Los Angeles, f is Salt Lake City, W are Hoover Dam and Sundance Resort, T is 7 days, B is $2,000. Everything else is unknown and must be discovered — c are other unknown interesting points I would appreciate, p is See & Do at the points (including s, f, points from W that will make it into the trip plan, and new points that emerge).

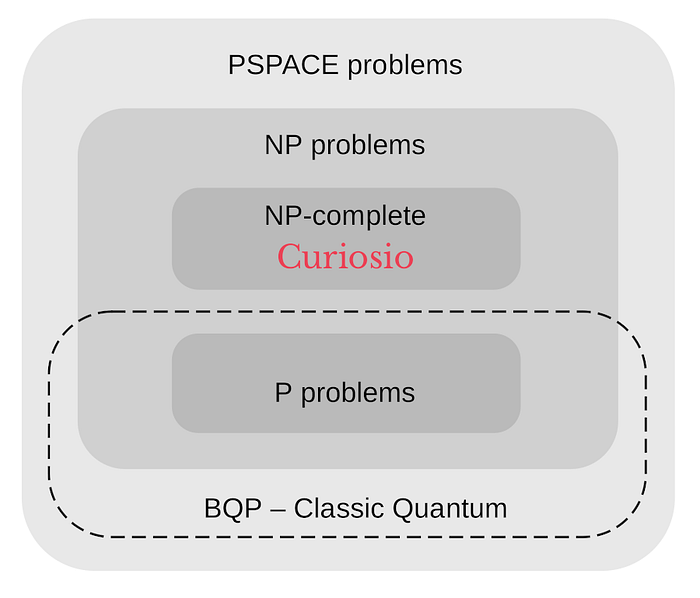
The math shows strenuous plexus of the three problems that are hard themselves. It is multimodal optimization of NP-Complete computational complexity of MOO+CSP+TSP (where MOO is multi-objective optimization, CSP is constraint satisfaction problem, TSP is traveling salesman problem).
There is order of magnitude more sophisticated model in the Lab, that handles points you want to avoid (e.g. do not visit Las Vegas), pin points to dates (e.g. I want to be at Sundance Resort on 16th of June), duration at each point, including defined number of days and ranges (closed and half-opened, e.g. 1–3 days, 2+ days, 3- days). This would make the model even more complicated, so I omitted it intentionally.
Quantum Shortcut?
It is easy on quantum. Joke, it is Ising on quantum. I usually play these words when I talk about the quantum optimization.

Quantum annealing could be useful, as it is kind of equivalent to simulated annealing, which is applicable to any optimization problems on classic silicon chips. There is research Ising formulations of many NP problems by Andrew Lucas in 2014, Department of Physics, Harvard (now he is at CU Boulder). It includes 20+ NP-complete problems. That work might be useful in designing adiabatic quantum optimization algorithms, e.g. for D-Wave chip, but the devil is in details…
The size of D-Wave chip is simply way insufficient for embedding of Curiosio math. The partitioning is not applicable because Curiosio model is multi-level and interconnected throughout the hierarchy.
But let’s imagine that D-Wave chip has trillion cubits. D-Wave chip topology is very specific, called chimera graph. There are no connections all-to-all. The embedding on the fully functional chimera is an optimization problem itself. There are dead qubits and broken links in reality, so the embedding becomes 10x harder problem. E.g. there were ~95% qubits and ~91% couplers operational at Los Alamos National Lab, D-Wave with 1000 qubits on 2X chip:

Embedding on real topology is hard but it is the smallest issue. Overall performance is still questionable on complicated models. Not suitable for Curiosio math for next several years or longer, mainly because of impossibility of partitioning and low number of qubits to avoid partitioning.
What about the classical quantum chips by Rigetti, Google, IBM? It is BQP — Bounded-error Quantum Polynomial time — the class of decision problems solvable by a quantum computer in polynomial time (with an error probability of at most 1/3 for all instances). What is the relation between BQP and NP-complete problems? It is not known for sure, but it looks not favorable for our model — BQP and NP-C problem spaces are disconnected:
Faster Irreducible
Some irreducible computations can be sped up by performing them on faster hardware, as the principle refers only to computation time.
— Stephen Wolfram
The biggest problem with NP-C problem is unpredictable time. In almost all cases it is longer unpredictable time than shorter. We invent and engineer AI engine Ingeenee — to deliver solution of NP-C problem almost as predictably in real-time as P problem. Ingeenee is evolutionary AI. Then the predictable irreducible workload could be sped up on faster hardware.
Quantum chips is no go for us, we have to stick to classic chips. These chips continue to evolve. The clock speed is not rising, mainly because of overheat and high power consumption. But the number of cores steadily increases. We tested Xeon Phi with 256 vcores at 1.5GHz back in 2018 and we loved it. 8 huge chips in one 2U box is possible even with air cooling (e.g. Fujitsu CX600 M1 server with 8 CX1640 M1 nodes). 256–512 2GHz cores per chip sounds feasible in the years to come. Come on Jim Keller \m/

Time Shift
And one more thing. By predicting what user will ask for we can compute in advance — hence shift the irreducibility back in time. Irreducibility remains, but for the end user it reduces more and more, until it vanishes.
